この投稿では、ChatGPTをはじめとする、生成型AIの仕組みについてごく簡単に解説します。
生成型AIとは?
生成型AI(Generative AI, Gen AIとも)とは、入力された指示(プロンプトと言います)によって何かを作り出す機能をもつAIのことです。
ChatGPTの場合、プロンプトの指示に従って、テキストを生成します。これによってまるで人間と会話をしているかのようなチャットをすることができます。
ChatGPTはバージョンによって、テキストだけでなく、画像の認識や解釈もすることができます。このように、さまざまなメディアに対応するAIをマルチモーダルモデルと呼びます。
プロンプトから回答を導く仕組み
ChatGPTはどうやって私たちのプロンプトに適した回答を生成することができるのでしょうか?
AIは膨大な量の学習用データを読み込み、そこからデータの中にあるパターンを学習します。
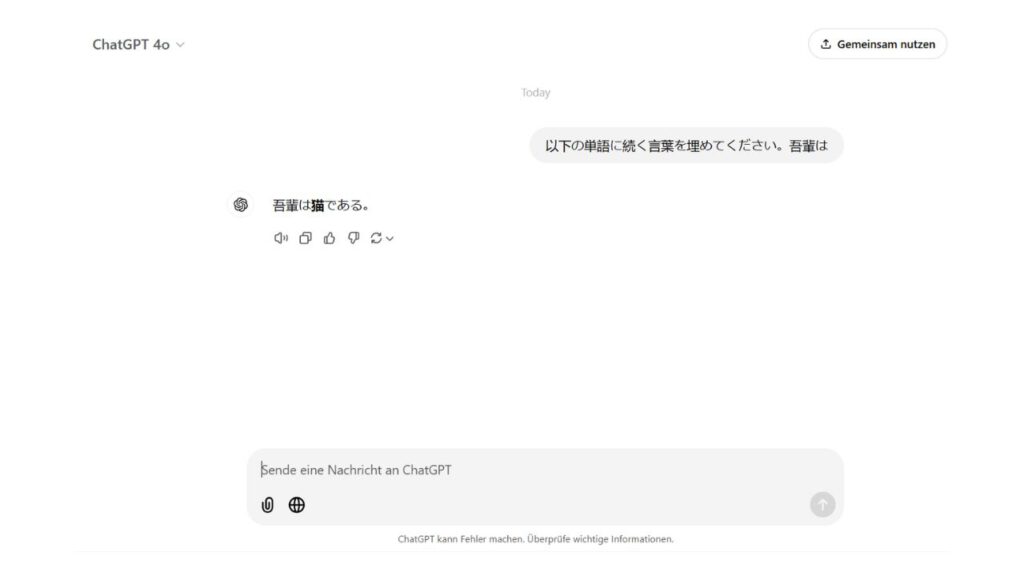
たとえば、「吾輩は」という言葉の後には「猫である」と続くデータが大量にある場合、「吾輩は」の後にくる言葉は「猫である」となる確率が高い、ということを学習していくわけです。
こうした学習に基づき、私たちがプロンプトに「吾輩は」と入力するとChatGPTは「猫である」と回答します。
基本的に、テキストを生成するAIは、学習したデータに基づき、前の単語に続くと思われる単語を順番に並べているだけです。しかしAIが学習するデータは、人間が同じ量の学習をすると十万年かかるといわれています。これだけの量のデータを学習すると、自然な受け答えができるくらいのパターンを身につけられるというわけですね。
ChatGPTの限界
ChatGPTは情報を調べるだけでなく、悩みごとの相談相手としても便利なツールです。しかしChatGPTにも限界があります。
まず、先ほどテキストを生成するAIは確率論に基づいて単語を並べている、という説明をしました。学習データから、この単語の次はこれが来る確率が高いと判断しているわけです。
ところでChatGPTに質問したところ、「吾輩は」の後に続く言葉が「猫である」となる確率は恐らく70%くらいだそうです。つまり30%の確率で別の言葉になる可能性もあるわけです(この回答も変動する可能性があるので、70%という数字も正確ではないかもしれません)。
このように、生成型AIの回答はいつも同じとは限りません。これは欠陥ではなく、多様なプロンプトに対応できるようにするための仕様なのです。ChatGPTの回答がいつも正しいわけではないということは常に頭の中に入れておく必要があります。
また、どのAIも「データカットオフ」というものがあります。学習データは膨大な量なので、「いつからいつまでの情報」とデータを制限しないと効率的な学習ができません。たとえばChatGPTのGPT-3.5モデルは2021年以降の情報は学習していない場合があります。このため、このモデルに2022年のデータを尋ねても正確な回答はできません。
ChatGPTのGPT-4モデルになると、2023年頃のデータまで学習しています。
ChatGPTに限らず、AIを利用する際は、その能力の限界も知っておくことが大切です。
最終的には自分の目と耳で情報を確かめること、AIの回答をそのままうのみにしないことを心がけるようにしましょう。AIはあくまで補助ツールであり、利用の責任は常にユーザーにあるのです。